


Basics of database indexing
At some point, we have all been there: a perfectly functioning application suddenly slows down as your database grows. The application, which previously worked on lightning speed queries with 10,000 records, now takes forever with 10 million records. The culprit? Missing database indexes.
Database indexing can transform sluggish table scans into lightning-fast lookups by creating optimized data structures that act as shortcuts to your information. Think of it as the difference between flipping through every page of a phone book versus jumping directly to the right section using the alphabetical tabs, except the performance difference can be measured in milliseconds versus minutes.
Understanding the basics of database indexing and its various types will allow you to significantly improve query performance for large databases.
In this article, we introduce database indexing and explore the different types of indexing techniques, and demonstrate practical implementations that can dramatically improve your query performance.
What is database indexing, and how does it work?
A database index is a supplementary data structure that provides quick reference for specific columns, allowing the database to locate data without scanning the entire table.
The index is structured as a sorted list of values from the indexed columns, where each value is linked to a pointer that directs to its corresponding row in the main table. When you query the database, it first looks up this sorted index to find the desired values, then uses the stored pointers to directly access the relevant rows in the table.
Most indexes use a "B-tree" structure, which organizes data in layers, allowing the database to quickly narrow down its search by following branches. Some indexes, especially for unique values, use a hash table, which converts values into unique codes pointing directly to rows.
But since the index is a separate structure, it uses additional storage space in the database, and it also needs to be updated whenever data in the indexed columns changes. Different database systems may implement these storage and update mechanisms differently.
Why do we need database indexing?
Indexes improve database search performance by eliminating the need for full table scans. Without an index, when you query a database, it must sequentially check each row until it finds the data you are looking for. An index allows the database to quickly locate records by referencing the sorted structure, which is especially useful for efficiently handling WHERE clauses without scanning every row. This dramatically improves query performance, especially for large data sets where sequential scanning would be impractical.
For example, when you're searching for a customer by their phone number in a database with millions of records, an index on the phone number column allows the database to pinpoint the matching records instantly.
While indexes significantly improve read performance, they come with a trade-off. Whenever you insert, update, or delete data in an indexed column, the database must also update the associated index structures. This adds extra disk I/O and processing overhead, which can slow down write operations. Thus, it's essential to carefully weigh these trade-offs when deciding which columns to index.
Types of indexes
This section discusses three index types that can improve the performance of SQL queries.
B-tree indexes
B-trees are a widely used index type in databases to organize data in a sorted, layered structure. This self-balancing tree structure allows databases to locate specific rows quickly, avoiding the need to scan entire tables.

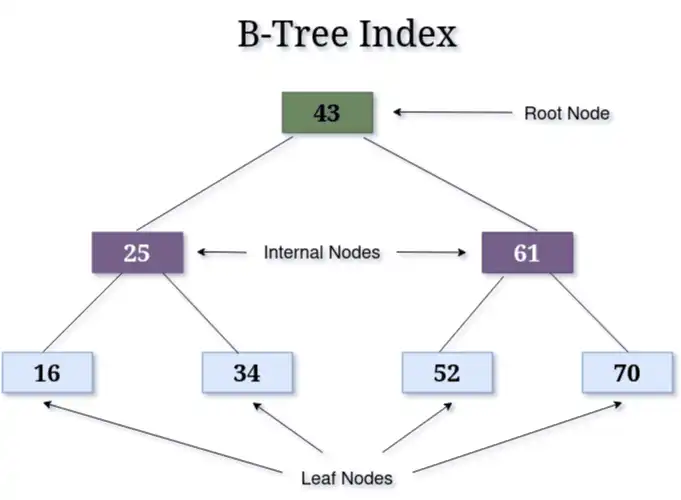
As shown in the diagram, B-trees organize data into smaller, sorted sections across different branches. Values are arranged from lowest (on the left) to highest (on the right). This structure makes them well-suited for efficient range queries and rapid lookups. As data is added, the B-tree adjusts its branches and nodes to maintain its sorted, balanced form, which also ensures that lookups remain efficient even as the database grows.
The database uses the indexed value as a B-tree key and stores a pointer to the record as the B-tree value. When you search for a record with a specific value, the database finds the matching key, retrieves the pointer, and then gets the record.
The B+ tree is a variation specifically designed for database storage systems. Unlike standard B-trees, B+ trees store all data only in leaf nodes and link these leaves together. This structure makes B+ trees ideal for range queries and table scans, which is why most database engines (like MySQL's InnoDB) use B+ trees rather than standard B-trees for their indexes.
Did you know? Many popular databases, such as MySQL, PostgreSQL, and Oracle, use B-tree or B+ tree indexes as their default indexing method, including for primary keys.
Hash indexes
Hash indexes differ from B-trees in their underlying mechanism. They use a hash function, a mathematical algorithm that converts input data into a unique code, or hash, representing that data.
Hash indexing works in two steps:
- The indexed column value is passed through the hash function to generate a unique hash code.
- This hash code serves as a pointer to the row's location in the database table.
The diagram below illustrates how hash indexes map hashed values to database locations.

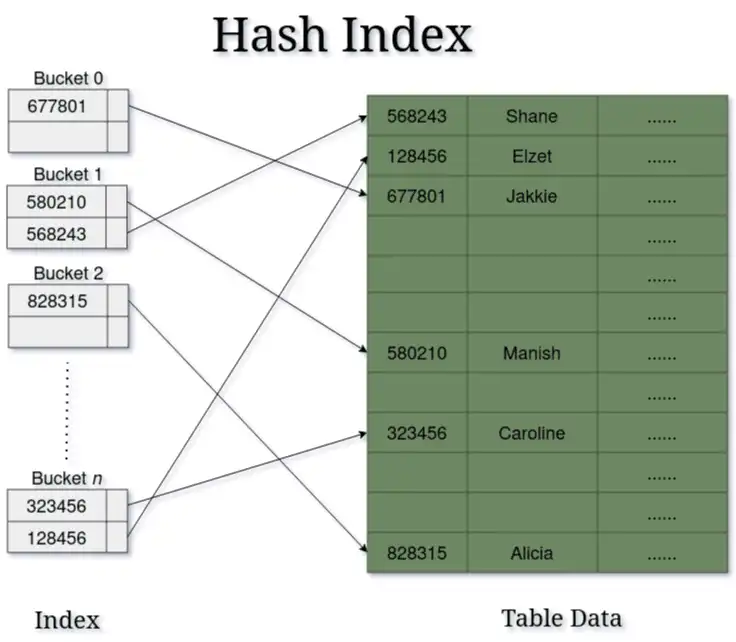
This direct-mapping approach allows for constant-time O(1) lookups, making hash indexes especially efficient for exact-match queries, such as finding a specific customer ID or order number with WHERE column = 'value' clauses.
However, hash indexes have a critical limitation: they only work for exact matches. Since hash functions scramble the natural order of data, you cannot use hash indexes for range queries (like WHERE age > 25), sorting operations, or pattern matching. This makes them unsuitable for most real-world scenarios where you need flexible querying.
Full-text indexes
Full-text indexes are specialized indexes that make searching large text fields much faster by indexing individual words (terms) within a text column. Rather than treating a text as a single entity for an exact match, a full-text index breaks it into searchable terms, which improves the database's speed when handling complex text searches, like finding all records containing a specific word or phrase.
A commonly used structure for full-text indexing is the inverted index, which essentially maps words (or terms) to the documents containing those words. For instance, if we have three documents and the first and the second one contain the word strawberry, then the mapping would show strawberry pointing to documents 1 and 2.
Here is a simple illustration of this concept:

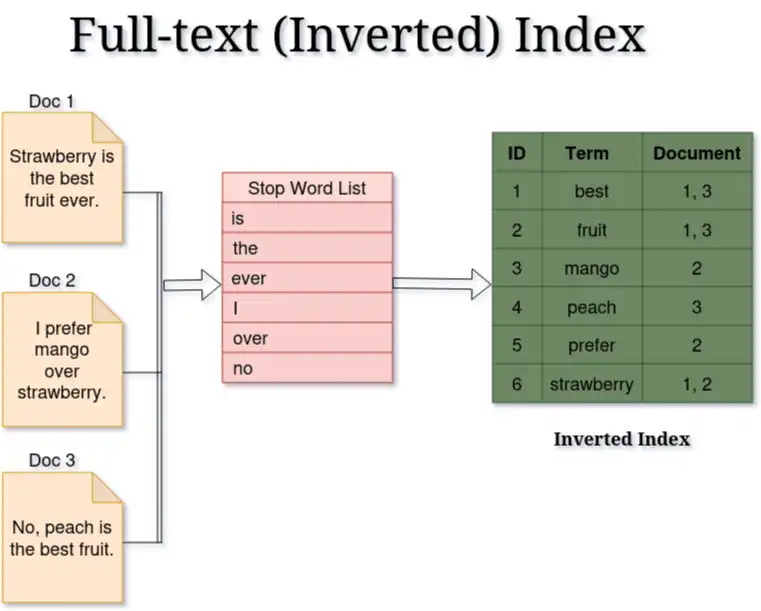
Note: Full-text indexes typically ignore common words like "the," "is," and "and" (called stop-words) to save space and improve search performance. By ignoring these frequent, low-importance words, the index can save space and increase search efficiency.
Full-text indexes are particularly useful for applications that require advanced search capabilities. They are ideal for searching large volumes of text, such as finding specific keywords in articles, identifying features in product descriptions, or locating phrases within user messages. Consider creating a full-text index on a large text field if an application needs to search within its content. For example, you might add a full-text index to the product_description field if users frequently search for product features, such as bluetooth or wireless.
But, full-text indexes take up significantly higher storage space and require ongoing maintenance as text data is added or updated. They're also slower for simple exact-match queries compared to other index types, making them best suited for text search operations.
Clustered and nonclustered indexes
Indexes can also be classified into clustered and nonclustered (secondary) indexes. A clustered index defines the physical order of data in a table, and a table can have only one clustered index. Nonclustered indexes are stored separately, with pointers to the relevant rows, and a table can have multiple nonclustered indexes. Think of a clustered index as the entire book organized in a specific order (like a phone directory, sorted alphabetically), while nonclustered indexes are like bookmarks that point to relevant pages.
Did you know? In MySQL (InnoDB), the primary key serves as the clustered index by default. In PostgreSQL, there are no true clustered indexes; every index, including the primary key, is technically a secondary index.
When to use indexes and when to avoid them
Indexes are most effective on columns that are frequently searched, sorted, or used in JOIN operations, such as primary keys, foreign keys, or fields in WHERE clauses. One best practice is to create indexes on columns that are used to filter large data sets (such as age and experience level) and improve query performance. Additionally, consider indexing columns involved in sorting (ORDER BY) or aggregation (GROUP BY) as these operations benefit from faster data access through indexes. Indexes can also be valuable for columns involved in aggregations (SQL functions such as SUM(...) and AVG(...)), where summarizing data could become a bottleneck without quick access paths.
But indexes add storage and maintenance overhead, so be careful when using them on frequently updated tables. If a table is constantly being inserted into or updated, each change requires the index to be modified, which can slow down write operations. Avoid creating indexes on columns with low selectivity, such as Boolean or binary fields, as they have few distinct values, providing little performance benefit while adding unnecessary overhead. Finally, for very small tables, indexing is often unnecessary as the database can quickly scan the entire table without a noticeable performance impact.
Real-world examples of database indexing
Let's take a look at some real-world examples of database indexing. The following sections use a basic SQL table to demonstrate how indexing can improve query performance. These examples use standard SQL syntax unless mentioned otherwise.
Here's a basic "users" table with columns for name,email, age, bio, and id as the primary key:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE,
age INT,
bio TEXT
);
B-tree index example
Suppose you frequently query the age column to find users in a specific age range, such as those aged between twenty-five and thirty-five. A typical query for this would be as follows:
SELECT * FROM users WHERE age BETWEEN 25 AND 35;
Without an index, the database performs a full table scan, checking each row to see if the age falls within the range. This approach can be very slow as the table grows larger.
To optimize such queries, you can create a B-tree index on the age column:
CREATE INDEX idx_age ON users(age);
Note: B-tree is the default index type in both MySQL and PostgreSQL, so when you create a standard index, it's typically a B-tree index.
With this index in place, the database can navigate the sorted age column using the B-tree structure. This allows it to skip irrelevant rows and focus only on those matching the query conditions. For range queries like BETWEEN, B-tree indexes are particularly effective as they're designed to support ordered data access.
Thus, if you run the same query with the index, the database workload is significantly reduced, resulting in faster query execution. This performance gain becomes increasingly important as the table grows larger.
Hash index example
Another common use case is searching for users by their email, for example, during a login process. Since email addresses are unique and looked up exactly, hash indexing can be an effective solution for exact-match queries.
Here is a query that finds a user by email:
SELECT * FROM users WHERE email = 'jane.doe@example.com';
Without an index, the database has to check each row's email field to match the exact value, which can be very slow for large tables.
To ensure good performance on this crucial query, you can create a hash index with the following SQL:
CREATE INDEX idx_email_hash ON users USING hash(email);
If you rerun the same query now, with the index in place, the database directly jumps to the matching email row (or checks the specific hash), significantly speeding up exact matches.
Again, the database no longer has to scan each row; instead, it uses the hash index to directly locate the matching row, making exact lookups extremely efficient, especially for large data sets.
So any applications with large numbers of users that log in with their email addresses would benefit greatly from a hash index on the email field.
Note: Hash indexes are natively supported in PostgreSQL, but MySQL doesn't have native hash indexes. Even when you ask an InnoDB table to create a hash index, it turns it into a B-tree.
Full-text index example
Lastly, imagine you have a user database with engaging bios, and you want to find users interested in movies.
A common query for this would be as follows:
SELECT * FROM users WHERE bio LIKE '%movies%';
Without a full-text index, this query requires scanning each row's bio field and checking if it contains the specified text (using the ‘%keyword%’ pattern), which can be extremely slow for large text fields.
If you need to frequently search for specific keywords within large text fields in a database, creating a full-text index can greatly improve performance.
The syntax for creating a full-text index differs between databases. Here's how to create one in PostgreSQL and MySQL:
-- PostgreSQL
CREATE INDEX idx_bio_fulltext ON users USING GIN (to_tsvector('english', bio));
-- MySQL
CREATE FULLTEXT INDEX idx_bio_fulltext ON users(bio);
MySQL has built-in support for full-text indexing on VARCHAR and TEXT columns. In PostgreSQL, you create a full-text index using the Generalized Inverted Index (GIN) on the result of the to_tsvector function.
With the full-text index in place, you can now run full-text search queries to find users interested in movies:
-- PostgreSQL
SELECT * FROM users WHERE to_tsvector('english', bio) @@ to_tsquery('movies');
-- MySQL
SELECT * FROM users WHERE MATCH(bio) AGAINST ('movies' IN NATURAL LANGUAGE MODE);
With a full-text index, the database can search for keywords within large text fields, eliminating the need to scan every row. This makes keyword searches much faster, particularly when dealing with large text-heavy columns.
Conclusion
Database indexing isn't just a performance optimization; it's often the difference between an application that scales and one that crashes under load. The techniques we've covered today can transform your slowest queries into lightning-fast operations, but only if you implement them strategically.
So, what’s the next step? Start by identifying your application's most frequent queries and heaviest traffic patterns. Focus on indexing columns that appear in WHERE clauses, JOIN conditions, and ORDER BY statements. Remember, every index is a trade-off between read speed and write performance; choose wisely.
But here's the reality: managing database performance optimization across multiple environments, monitoring query patterns, and maintaining indexes as your application evolves can quickly become overwhelming. You need more than just indexing knowledge; you need a platform that makes performance optimization seamless.
This is where Upsun transforms your development workflow. Instead of juggling database configurations across staging and production, Upsun provides instant environment cloning with real data, so you can test your indexing strategies against actual query patterns before they go live. With built-in observability profiling, you'll spot performance bottlenecks instantly and get actionable recommendations for optimization.
Ready to stop guessing about database performance? Start your free Upsun trial and experience what it's like to optimize with confidence, complete with the tools and insights that make database performance management effortless.