


RESTful APIs ermöglichen Client-Anwendungen den Zugriff auf und die Bearbeitung von Ressourcen (Daten), die auf einem remote Server gehostet werden, unter Verwendung eines standardisierten Satzes von Regeln und Protokollen. REST steht für Representational State Transfer und ist eine Reihe von architektonischen Prinzipien, die festlegen, wie diese Schnittstellen zu gestalten und zu implementieren sind. Zu den wichtigsten Prinzipien des RESTful-Designs gehören die Verwendung von HTTP-Methoden wie POST, GET, PATCH und DELETE zur Durchführung von CRUD-Vorgängen (Erstellen, Lesen, Aktualisieren, Löschen), die Identifizierung von Ressourcen durch eindeutige URLs und die Übertragung von Daten in einem leichtgewichtigen Format wie JSON. RESTful APIs bieten eine flexible und standardisierte Möglichkeit für Systeme, über das Internet miteinander zu kommunizieren, was sie zu einem grundlegenden Baustein moderner Web- und Mobilanwendungen macht.
Dieser Artikel behandelt die Grundlagen des RESTful-API-Designs. Am Ende werden wir die wichtigsten REST-Prinzipien erforschen, wie sie sich von anderen Paradigmen unterscheiden, sowie die Best Practices für die Entwicklung von RESTful-APIs.
API-Designprinzipien
Bevor wir uns mit den Details befassen, wollen wir kurz darauf eingehen, wie RESTful im Vergleich zu anderen gängigen API-Design-Methoden abschneidet.
RESTful
Wie bereits erwähnt, sind REST-APIs eher um Ressourcen (Nomen) als um Aktionen herum strukturiert und verwenden Standard-HTTP-Methoden (GET, POST, PUT, DELETE), um diese Ressourcen zu manipulieren. RESTful-APIs basieren auf mehreren Schlüsselprinzipien für konsistente und skalierbare Web Services:
- Zustandslose Kommunikation. REST-API-Aufrufe enthalten alle erforderlichen Informationen, ohne dass der Client-Kontext zwischen den Aufrufen auf dem Server gespeichert wird.
- Einheitliche Schnittstelle. Dieser Grundsatz gewährleistet eine konsistente Ressourcenidentifizierung und -manipulation durch selbstbeschreibende Nachrichten unter Verwendung von Standard-HTTP-Headern und Statuscodes. Es ermöglicht auch die Integration von HATEOAS (hypermedia as the engine of application state), das es den Clients ermöglicht, APIs dynamisch zu entdecken.
GraphQL
GraphQL, entwickelt von Facebook, ist eine Query-Sprache und Laufzeitumgebung, die einen effizienteren und flexibleren Datenabruf als herkömmliche REST-Endpunkte ermöglicht. Die wichtigsten Designprinzipien sind:
- Query Flexibilität. Dadurch können Kunden angeben, welche Daten sie in der Response benötigen. Dies bedeutet, dass mehrere Ressourcen in einer einzigen Abfrage angefordert werden können, wobei ein Over- oder Underfetching von Daten vermieden wird.
- Single-Endpunkt-Architektur. Alle Requests werden über einen Endpunkt geleitet, wobei die Operationen nach Query- und Mutationstypen unterschieden werden. Ein Schema definiert alle möglichen Operationen und Typen innerhalb der Architektur.
- Starkes Typisierungssystem. Es dient als Vertrag zwischen Client und Server und bietet eine integrierte Typvalidierung und -dokumentation, während es gleichzeitig leistungsstarke Developer Tools und Typüberprüfungen ermöglicht.
gRPC
gRPC wurde von Google entwickelt und ist ein RPC-Framework (Remote Procedure Call), das auf HTTP/2 basiert. Es basiert auf den folgenden Grundprinzipien:
- Contract-first-Entwicklung. Verwendung von Protocol Buffers (protobuf) als strikte interface definition language (IDL), die eine automatische Codegenerierung sowohl für Client- als auch für Serverimplementierungen ermöglicht.
- Unterstützung von Streaming. Umfasst einheitliche, Server-, Client- und bidirektionale Streaming-Fähigkeiten, die es effizient für Echtzeitkommunikation und große Datenübertragungen machen, insbesondere bei der Kommunikation von Microservices.
- Binäres Protokoll. Es verwendet HTTP/2 als Transportschicht, die eine hocheffiziente binäre Serialisierung bietet. Dies führt zu geringeren Latenzzeiten und besserer Leistung im Vergleich zu textbasierten Protokollen.
Überblick über die API-Designprinzipien
Die folgende Tabelle fasst einige der Unterschiede zwischen diesen Entwürfen zusammen:
| REST | GraphQL | gRPC | |
| Anwendungsfälle | Am besten für CRUD-Vorgänge (Erstellen, Lesen, Aktualisieren, Löschen) und Standard-Ressourcenabrufe | Am besten geeignet für komplexe Queries und Szenarien, in denen Kunden spezifische Daten benötigen werden | Am besten geeignet für Microservices und Hochleistungsanwendungen, die Echtzeitkommunikation erfordern |
| Datenformat | unter anderem JSON und XML | JSON | Protokollpuffer |
| Stil des Requests | Ressourcenorientiert (CRUD) | Queryorientiert | Prozedurorientiert |
| Zwischenspeicherung | Eingebautes HTTP-Caching | Benutzerdefinierte Implementierung erforderlich | Benutzerdefinierte Implementierung erforderlich |
| Typsicherheit | Keine eingebaute Typensicherheit | Starkes Typsystem | Starkes Typsystem |
| Fehlerbehandlung | Standard-HTTP-Statuscodes | Benutzerdefinierte Fehlerantworten über JSON | Benutzerdefinierte Fehlerbehandlung über Protokollpuffer |
RESTful-API-Architekturüberblick
Ein System, das eine RESTful-API verwendet, umfasst in der Regel drei Hauptkomponenten: den Client, den Server und die Datenbank. Es umfasst auch zusätzliche Elemente wie einen Loadbalancer, Caching und einen Authentifizierungsdienst.

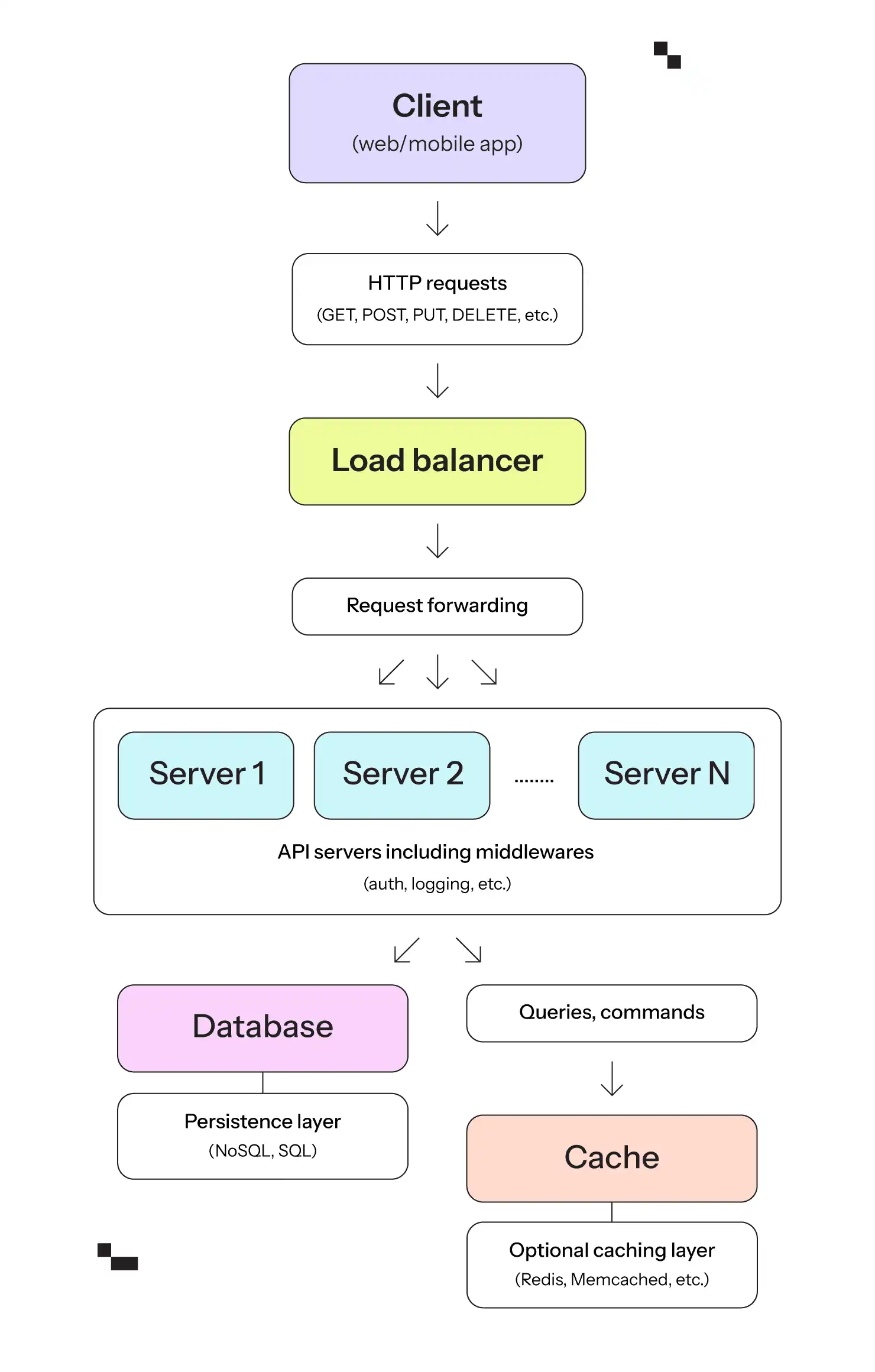
Client
Der Client ist jede Anwendung oder jedes Gerät, das die API nutzt. Dabei kann es sich um einen Webbrowser, eine mobile Anwendung oder einen anderen Server in einer Microservices-Architektur handeln. Clients senden mit Hilfe von HTTP-Methoden (z. B. GET, POST, PUT, DELETE) Requests an den Server, um CRUD-Operationen an Ressourcen durchzuführen, z. B. eine mobile Anwendung, die Benutzerdaten durch eine GET-Requests an https://api.example.com/users abruft.
API-Server
Der Server hostet die API und ist für die Verarbeitung eingehender Client-Requests, die Interaktion mit der Datenbank oder anderen Diensten und die Rückgabe von Reponses verantwortlich. Der Server interpretiert die HTTP-Anforderungen, führt die erforderlichen Operationen durch (z. B. Erstellen, Abrufen, Aktualisieren oder Löschen von Ressourcen) und gibt die entsprechenden HTTP-Statuscodes und Daten zurück.
Middleware ist eine optionale Schicht, die in die Serverarchitektur integriert werden kann, um zusätzliche Funktionalitäten zu handhaben. Dazu können Authentifizierung, Protokollierung, Datenvalidierung, Fehlerbehandlung und Request/Response-Umwandlungen gehören. Middleware verarbeitet Requests, bevor sie die Kernlogik des Servers erreichen, und kann auch Reponses ändern, bevor sie an den Client zurückgesendet werden.
Datenbank
Die Datenbank speichert die Anwendungsdaten. Dabei kann es sich um eine relationale Datenbank (wie PostgreSQL oder MySQL), eine NoSQL-Datenbank (wie MongoDB) oder eine andere Form der Datenspeicherung handeln. Der Server verwendet die Datenbank zum dauerhaften Speichern und Abrufen von Daten, wie z. B. Benutzerinformationen, Produktdetails oder Transaktionshistorien.
Innerhalb der Datenbank speichert eine Caching-Schicht Kopien häufig angeforderter Daten, um die Notwendigkeit eines wiederholten Zugriffs auf die Datenbank zu verringern. Sie trägt zur Verringerung der Latenz bei, indem sie Daten aus dem Cache bereitstellt, anstatt die Datenbank jedes Mal abzufragen. Dies wird häufig mit In-Memory-Datenbanken wie Redis oder Memcached erreicht.
Loadbalancer
Ein Load Balancer kann verwendet werden, um eingehende Client-Requests auf mehrere Serverinstanzen zu verteilen. Dies trägt zu einer hohen Verfügbarkeit und Skalierbarkeit bei und verhindert, dass ein einzelner Server zu einem Engpass wird. Er gleicht den Datenverkehr zwischen mehreren Serverinstanzen aus, um die Antwortzeiten zu verbessern, bietet Fehlertoleranz, indem er Requests umleitet, wenn ein Server nicht mehr reagiert, und kann auch die SSL-Terminierung übernehmen, um die Ver- und Entschlüsselung von den Servern zu entlasten.
Hauptmerkmale von REST-APIs
REST-APIs beruhen auf mehreren Grundprinzipien, die ihre Architektur und ihr Verhalten bestimmen.
Client-Server-Architektur
In einer RESTful-API-Architektur arbeiten der Client und der Server unabhängig voneinander. Der Client (z. B. ein Webbrowser oder eine mobile Anwendung) ist für die Benutzeroberfläche verantwortlich und sendet Requests, während der Server die Datenverarbeitung und die Reponses übernimmt. Diese Trennung von Belangen führt zu langfristiger Wartbarkeit und Flexibilität.
So kann beispielsweise eine mobile Anwendung mit dem REST-Server über dessen API interagieren, ohne die Implementierungsdetails verstehen zu müssen. Wenn die Backend-API Code für die Benutzeroberfläche enthält, entsteht eine enge Kopplung zwischen Client und Server, was zu Abhängigkeitsproblemen führt und Aktualisierungen erschwert.
Zustandslose Kommunikation
Wie bereits erwähnt, enthält in einer zustandslosen Architektur jeder Request vom Client an den Server alle Informationen, die zur Verarbeitung des Requests erforderlich sind. Der Server speichert keine clientspezifischen Sitzungsdaten. Dies erleichtert der API-Server-Schicht die horizontale Skalierung. Da jeder Request in sich abgeschlossen ist, können die Server sie unabhängig voneinander bearbeiten, was den Lastausgleich vereinfacht. Das bedeutet auch, dass die Server den Sitzungsstatus nicht speichern müssen, was den Speicher-Overhead reduziert.
So muss beispielsweise ein Login-API-Aufruf bei jedem Request die Anmeldedaten des Benutzers enthalten, anstatt sich auf eine auf dem Server gespeicherte Sitzungs-ID zu verlassen. Dadurch kann jeder Server in einem Cluster die Requests bearbeiten, ohne dass ein vorheriger Kontext erforderlich ist. Wenn ein Server auf Sitzungsdaten angewiesen ist, die zwischen den Requests gespeichert werden, erschwert dies die Skalierung und macht es Load Balancern schwer, die Requests gleichmäßig zu verteilen.
Cachebare Responses
Die Reponses von RESTful-APIs können gecacht werden, so dass Clients oder Vermittler die Reponses für eine bestimmte Zeit speichern können. Dadurch wird der Bedarf an wiederholten Requests für dieselben Daten minimiert. Zwischengespeicherte Daten können schneller bereitgestellt werden, als wenn sie jedes Mal beim Server abgefragt werden. Außerdem werden die Latenzzeit und die Serverlast verringert, was die Benutzerfreundlichkeit und Skalierbarkeit verbessert.
Eine API-Reponse kann Caching-Header wie Cache-Control und Expires enthalten, die es dem Client ermöglichen, die Daten vorübergehend zu speichern und unnötige Aufrufe an den Server zu vermeiden. Eine API-Reponse für das Wetter, die zwischengespeichert werden kann, kann beispielsweise die Notwendigkeit häufiger Aktualisierungen verringern, wenn die Daten eine Stunde lang unverändert bleiben. Fehlen Cache-Header in den Reponses , fordern die Clients wiederholt dieselben Daten an, was den Server unnötig belastet und die Antwortzeit für den Endnutzer verlangsamt.
Mehrschichtiges System
Ein mehrschichtiges System ermöglicht es APIs, über mehrere Schichten hinweg zu arbeiten, wie z. B. Vermittler, Load Balancer und Gateways, ohne dass der Client diese Schichten kennt. Dieser Ansatz bietet zusätzliche Sicherheit und Skalierbarkeit. Beispielsweise können Load Balancer bei der Verteilung des Datenverkehrs helfen, ohne dass der Client wissen muss, wie die Last verteilt wird. Diese Modularität macht es einfacher, Teile des Systems zu skalieren oder zu sichern, ohne die gesamte API umzugestalten.
Wenn ein Client eine API aufruft, kann er automatisch durch einen Load Balancer und eine Firewall geleitet werden, um eine optimale Leistung und Sicherheit zu gewährleisten, ohne dass der Client-Code geändert werden muss. Wenn ein Client direkt mit mehreren Backend-Servern interagieren oder verstehen muss, wie Requests verteilt werden, führt dies zu Komplexität und bricht die Abstraktionsebene auf.
Einheitliche Schnittstelle
Ein weiterer zentraler Grundsatz von REST-APIs ist die Bedingung der einheitlichen Schnittstelle, d. h. eine Reihe von Standardregeln für die Interaktion mit der API. Dazu gehören die einheitliche Verwendung von HTTP-Methoden (GET, POST, PUT, DELETE), Standard-URL-Muster und vorhersehbare Antwortformate. Eine einheitliche Schnittstelle verbessert die Benutzerfreundlichkeit der API, da es für Entwickler einfacher ist, vorherzusagen, wie die API auf Requests reagieren wird. Diese Konsistenz verringert die Lernkurve und die Wahrscheinlichkeit von Fehlern.
Eine RESTful-API verwendet ressourcenübergreifend einheitliche HTTP-Methoden (z. B. GET /users ruft Benutzer ab, POST /users erstellt einen Benutzer), was Einheitlichkeit und Vorhersehbarkeit gewährleistet. Eine API, die nicht standardisierte Methoden verwendet oder HTTP-Methoden vermischt (z. B. Verwendung von GET zum Erstellen einer Ressource), kann verwirren und die zuverlässige Verwendung der API erschweren.
On-Demand Code
Code on Demand ist eine optionale Einschränkung der REST-Architektur, die es Servern ermöglicht, die Client-Funktionalität zu erweitern, indem sie ausführbaren Code wie JavaScript zur Laufzeit an Clients übertragen, z. B. das Laden dynamischer Widgets oder die Aktualisierung von UI-Komponenten ohne Seitenaktualisierung.
Auf diese Weise kann der Client die Funktionalität dynamisch erweitern, ohne dass er seinen Code aktualisieren muss. Es bietet Flexibilität und kann die Funktionalität verbessern, indem es Clients erlaubt, Code direkt vom Server auszuführen, insbesondere in dynamischen Webanwendungen.
Fazit
In diesem Artikel wurde das Konzept der RESTful-API-Entwurfsprinzipien und die wesentlichen Komponenten, die eine API RESTful machen, untersucht. Dies begann mit einem Überblick über API-Designalternativen und einer Topologie einer typischen RESTful-Systemarchitektur sowie mit einem tiefen Einblick in die Schlüsselkomponenten von RESTful-APIs. Die Einhaltung von RESTful-API-Designprinzipien kann die Codequalität verbessern und sicherstellen, dass ihre APIs den Benutzern effektiv und effizient dienen, was ihre Anwendung langfristig erfolgreicher macht.
Upsun gibt modernen Entwicklungsteams die Freiheit, einfach zu experimentieren, schnell zu iterieren und mühelos in jeder Dimension zu skalieren. Es handelt sich um eine vollständig verwaltete, sichere, auf Entwickler fokussierte Cloud-Anwendungsplattform mit integrierter Observability, Multicloud-Edge-Caching, zuverlässigem Deployment und der Freiheit, ihren Stack und Cloud-Anbieter zu wählen. Mit Upsun können Sie RESTful-API-Anwendungen mit Programmiersprachen und Frameworks ihrer Wahl erstellen und ausführen. Sie haben die vollständige Kontrolle über die Skalierung von Anwendungen (horizontal oder vertikal), während Upsun die Schwerstarbeit, einschließlich der Ressourcenzuweisung und Datenverkehrsspitzen, verwaltet.